Hello World: Pipecat + Coval for Voice AI Testing
May 8, 2025

About Pipecat
Pipecat Cloud is a fully managed platform for deploying and scaling AI agents into production — purpose-built for the Pipecat framework. It simplifies launching agentic workflows and pipelines, with features tailored for modern Voice AI use cases:
Native support for agentic behavior and the full Pipecat ecosystem
Flexible deployment options and real-time observability
Blazing-fast performance, tuned for scale
Cross-platform SDKs for frictionless application development
Prebuilt templates and first-party integrations
Enterprise-grade security and compliance
Developed by Daily, Pipecat Cloud is backed by over a decade of infrastructure and real-time system experience.
✅ New integration: You can now connect your Pipecat agent directly to Coval — and run automated Voice AI evaluations and quality assurance tests with just a few clicks.
About Coval
Coval is the reliability infrastructure for conversational and Voice AI agents. Whether you’re building, testing, or monitoring an agent, Coval helps you evaluate performance, detect failures, and optimize conversation quality at every stage of the lifecycle.
Our platform is purpose-built for Voice AI testing and QA, with robust simulation, monitoring, and metric tooling.
Coval is designed for:
🧪 Developers & QA: Automate testing across hundreds of real-world voice scenarios, IVRs, accents, and interruptions
📊 Enterprise Agent Ops: Track voice agent performance across vendors and standardize quality benchmarks
⚙️ Fast-moving teams: Catch issues before they hit production with CI/CD integration and simulation loops
🔧 How to Connect Your Pipecat Agent to Coval
First, Create your agent by following Pipecat’s Quickstart guide.
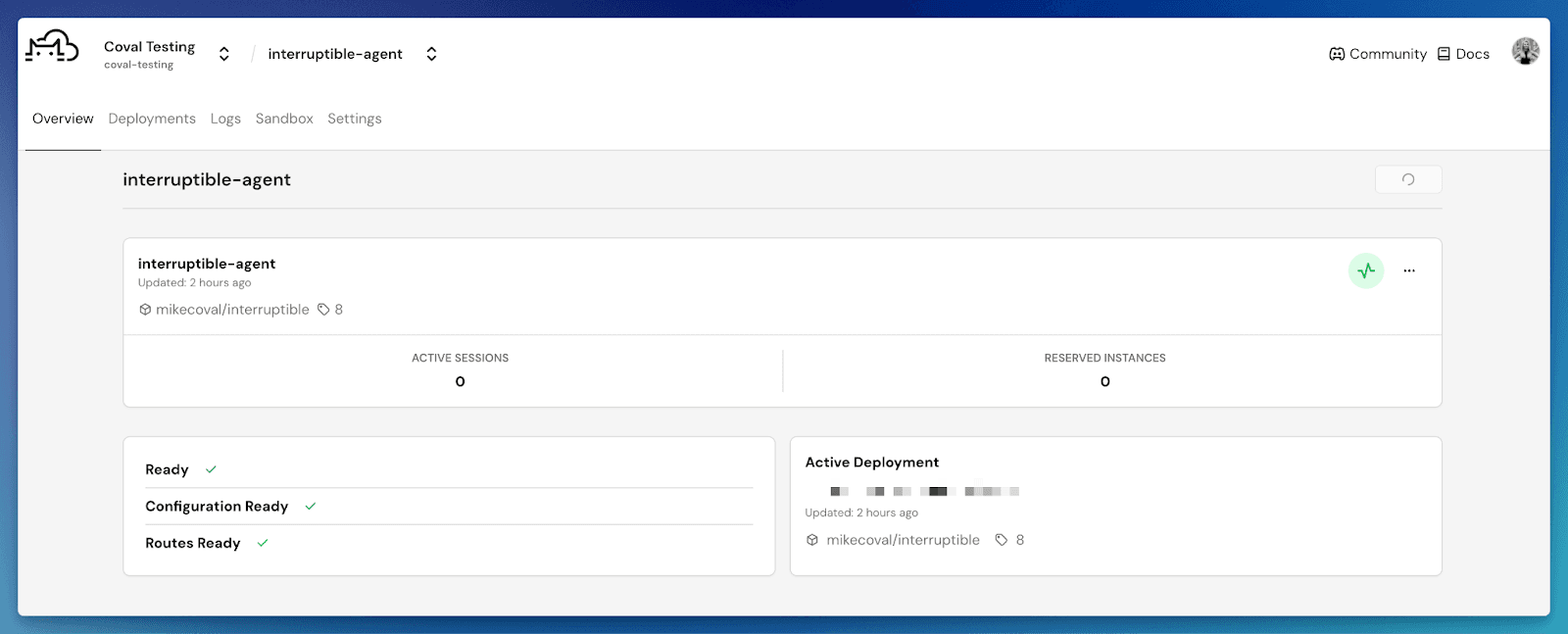
Once deployed, confirm your agent is listed in the Pipecat Agent Dashboard:
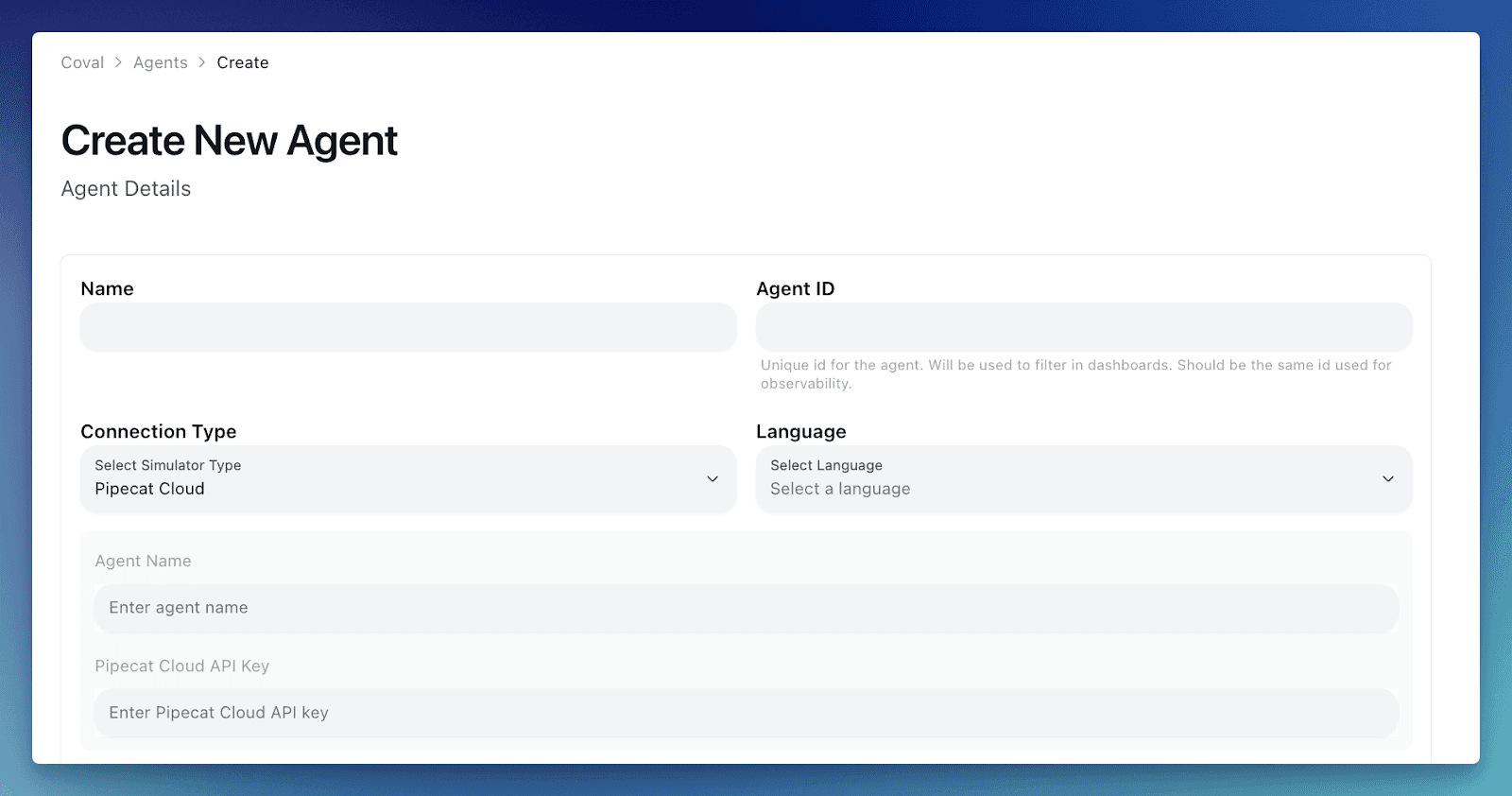
Next, head over to app.coval.dev/coval/agents/create and set up your Pipecat agent. Add your agent name, details, and make sure to add your Pipecat Cloud API key.
Note: The agent name must match the name used in your Pipecat deployment
That’s it! You’re good to go to launch your first evaluation 💪
🧪 Creating Evals for Your Pipecat Agent
Use Coval to launch simulated conversations with your Pipecat agent, and get rid of the need to manually call it every time your perform a change.
Coval lets you simulate conversations with your Pipecat agent and run repeatable Voice AI evaluations every time you make a change — no more manual testing.
1. Define what you’re testing — Test Sets
Test Sets let you simulate scenarios your agent should handle, like:
• “I want a refund”
• “Reschedule my doctor’s appointment”
• “Navigate to account settings via IVR”
You can script everything from basic flows to multi-turn, nuanced interactions.
✅ Pro Tip: Import real production transcripts for regression testing.
2. Define who we’re simulating — Personas
Personas allow you to test Voice AI agents against realistic, human-like behavior. Customize:
• Language, accent, voice style
• Emotional tone or background noise
• Interruption sensitivity and speech tempo
Example: Simulate a fast-speaking, Spanish-speaking customer who interrupts often — and test how your Voice AI handles it.
3. Define how to measure success — Metrics
Metrics are the foundation of high-quality Voice AI QA.
Coval provides:
Built-in metrics (e.g. latency, interruptions, speech tempo for audio evals)
Custom LLM-as-a-Judge metrics (e.g., Did the agent resolve the issue? Did it follow instructions? Was it repetitive?)
🎯 Run these metrics across both simulated and production calls — creating a continuous Voice AI evaluation loop that helps you spot regressions, track improvements, and ship confidently.
🚀 Ready to Level Up Your Pipecat Agent?
By connecting Pipecat to Coval, you unlock a powerful workflow for Voice AI testing, evaluation, and QA:
✅ Simulate real user conversations before deploying
✅ Run continuous metrics on live production voice calls
✅ Detect performance drift and regressions automatically
✅ Use consistent evaluation criteria across all environments
Whether you’re refining a new agent or managing complex customer flows, Coval helps you build reliable Voice AI experiences at scale.
🔗 Try it now: Reach out to the Coval team — we’re here to support your evaluation loop, from first simulation to full-scale monitoring.